On this page
Nimiq Validator Trustscore
warning
The Validator Trustscore is still under development and we are open to discuss changes to the algorithm.
The Validator Trustscore (VTS) helps users assess the reliability of validators in the Nimiq Wallet. This score ranges from 0 to 1, where 0 indicates a validator is not trustworthy, and 1 indicates a highly trustworthy validator. The VTS enables stakers to make informed decisions when selecting validators.
The VTS score is calculated using three key factors:
- Dominance: Ensures no validator has excessive influence by penalizing validators with a higher share of the total network stake.
- Reliability: Measures how consistently a validator produces blocks over the past nine months.
- Availability: Assesses how often a validator is online and actively selected to produce blocks.
info
The VTS evaluates validators' performance and reliability during block production. It does not assess staking pool reliability or reward payment processes. For insights into staking pools, refer to the Validators API or the Staking Pools Handbook.
The algorithm is designed to promote decentralization, fairness, and consistent network participation. Below is an example of how the VTS might appear in the Nimiq Wallet:
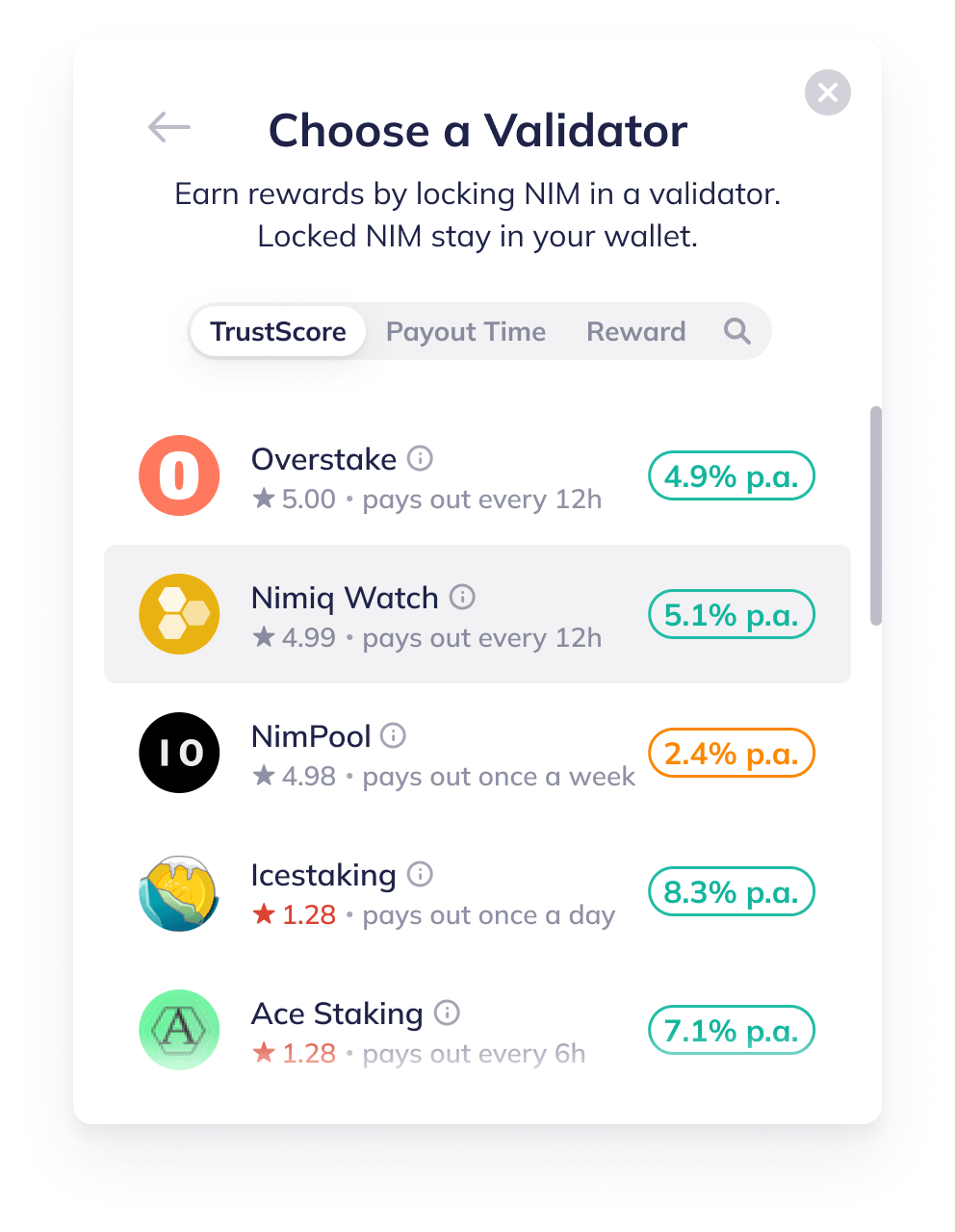
The VTS Technical Breakdown
The VTS algorithm uses three factors: Dominance, Reliability, and Availability. Each factor is calculated independently, with values ranging from 0 to 1, and their calculation determines the final score.
The dominance factor is based on the dominance of the validator's stake relative to the total stake in the network. Reliability and availability are based on behavior over the last nine months. For these parameters, only completed epochs are considered, not the currently active one. Therefore, the score is not live and can have a delay of up to 12 hours (an epoch lasts 12 hours).
Calculation of
Because reliability and availability are based on the behavior of validators over the last 9 months, we need to define 𝑚 the number of epochs to consider within this timeframe. This value ensures that all calculations include only completed epochs for accuracy. Where:
Block duration and blocks per epoch are constants defined in the policy.
info
The curves and constants presented in this document are subject to change at any time in the future. Any updates will be communicated to the community to ensure transparency.
Dominance
The dominance factor ensures that no single validator controls an excessive portion of the network's total stake. Validators with a larger stake receive a lower score to encourage a fairer distribution of control across the network. This approach penalizes disproportionately large stakes while promoting diversity in validator participation.
Dominance Ratio
The dominance ratio (
Active Epoch Method: During an active epoch, the dominance ratio is determined by dividing the validator's share by the total network share:
Where:
: The validator's share. : The total network share.
This method relies on the getActiveValidators function from the RPC, which provides real-time balances of each active validator.
Finished Epoch Method: For a closed epoch, a less precise fallback method exists, but is not currently implemented. This approach calculates the dominance ratio based on slot distribution across voting blocks. The ratio is derived by dividing the number of slots allocated to a validator by the total slots in the epoch:
Where:
: The number of slots allocated to the validator. : The total number of slots in the epoch.
While this method is defined in the code as dominanceRatioViaSlots, it is not actively used in practice.
Curve adjustment
After determining the dominance ratio, a curve is applied to calculate the dominance score
Where:
is the threshold. is the slope of the curve.
Graph of the dominance factor. The x-axis represents the validator's dominance ratio, and the y-axis represents the dominance score.
The following table illustrates how the dominance score varies with the stake percentage:
| Stake Percentage | Dominance Score |
|---|---|
| 0% | 1 |
| 5% | 0.999 |
| 7.5% | 0.994 |
| 10% | 0.952 |
| 12.5% | 0.745 |
| >=15% | 0 |
Reliability
The Reliability factor measures how consistently a validator produces blocks when expected. Validators who reliably produce their assigned blocks will have a high score, while those who fail frequently will receive a lower score. The reliability score is calculated as a weighted moving average over multiple epochs, emphasizing recent performance.
Calculating Reliability for an Epoch
The reliability score for a single epoch
Where:
: The number of blocks produced by the validator in epoch that received rewards. : The expected number of blocks the validator was likely to produce in epoch .
Calculating
Where:
: The number of blocks produced by the validator in batch of epoch . : The total number of batches in the epoch (retrievable from the policy). The number of blocks a validator produced can be retrieved from the blockchain via the rewarded inherent of each batch.
Calculating
Where:
: The total slots assigned to the validator in epoch . : The total number of active validators in epoch .
Combining Reliability Scores Across Epochs
To calculate a validator's overall reliability score, we use a weighted moving average of scores across multiple epochs. More recent epochs are given higher weight:
Where:
: Total number of epochs considered. = 0.5: Parameter determining how much weight the oldest epoch receives compared to the newest epoch, helping to balance the influence of recent versus older performance tendencies in the weighted moving average.
Adjusting for High-Reliability Expectations
The formula for the weighted moving average
The adjusted reliability score
Where:
: Defines the slope of the arc and determines the position of the curve. The adjustment formula is based on a circular arc, with the center of the circle at .
This adjustment maps the reliability score to a curve, making penalties for lower scores sharper while preserving high scores for reliable validators.
Graph of the reliability score adjustment. The x-axis represents the reliability score, and the y-axis represents the adjusted reliability score. The adjustment curve is derived from a circular arc with a defined center.
For example, a baseline reliability score of
Note that using 10% is only a heavy approximation. The value of 0.9 could represent 10% downtime, but also 20% or 5%, depending on when the downtime occurred. We use 10% to provide a relatable scale for the reader.
Availability
The availability factor measures how often a validator is online and selected to produce blocks. Validators that are consistently selected and actively producing blocks receive a higher score, promoting reliable participation and network security.
Why Availability Matters
Without availability, a validator could have high dominance and reliability scores but still not actively contribute to the network. This would misrepresent their role in maintaining the network's operation. The availability factor ensures that only validators selected to produce blocks are evaluated, penalizing those that fail to participate effectively, whether due to inactivity, being jailed, or missing blocks when offline.
In this context, we cannot measure how long a validator is online but can only determine when they are selected to produce blocks. A validator may be considered active yet fail to produce blocks. Availability focuses on participation in block production, regardless of online or offline status. For instance:
- A validator might not produce blocks because it hasn’t been selected in a specific period.
- In the other hand, a validator may be offline, causing it to miss block production when selected.
Availability reflects how often a validator is selected to produce blocks, regardless of their online status.
How to Calculate Availability
The availability score for a single epoch
Where:
: The availability score for the most recent epoch. : The availability score for the oldest epoch.
To combine availability scores across epochs into a single value, we calculate a weighted moving average, where more recent epochs have higher weights:
Where:
: Total number of epochs considered. : Determines the relative weight of the oldest epoch compared to the most recent one.
Adaptation to support smaller validators
To support smaller validators in our PoS network, an adjustment curve is applied to the moving average. This reduces penalties for validators that are less frequently selected for block production, while still incentivizing active participation. This adjustment ensures fairness for smaller validators, encouraging them to stay active while maintaining accountability for all participants.
The adjusted availability score
Graph of the availability score adjustment. The x-axis represents the availability score, and the y-axis represents the adjusted availability score.
Suggestions & Feedback
Like everything in Nimiq, this algorithm is designed with the people in mind. We always welcome feedback and suggestions to make it even better. If you’d like to share your thoughts, feel free to open an issue or join our Telegram group.